
在2023年10月在线发表于《INFORMATION SYSTEMS RESEARCH》上的论文《Are Neighbors Alike? A Semi-supervised Probabilistic Collaborative Learning Model for Online Review Spammers Detection》(DOI: 10.1287/isre.2022.0047)中,实验室学者刘冠男副教授、吴俊杰教授以及南京审计大学伍之昂教授、华盛顿大学谭勇教授,针对虚假评论者检测问题,提出了一个半监督概率协同学习模型,文章的主要观点如下。
01
摘要
在线评论平台中,常常有评论者通过故意发布不真实的商品评级和评论,以获取不正当的经济利益,从而损害在线平台的可信环境。尽管已经有大量的方法被提出用来解决虚假评论者检测问题,但仍存在诸如标签稀疏、有偏,且评论者可能存在合谋等挑战。为此,基于普遍存在的虚假评论者的合谋行为与网络同质性理论,我们引入了一个评论者网络来建模评论者之间的共同评论关系,进而提出一个半监督概率协同学习模型,以同时刻画评论者的个体行为特征和评论者网络。该模型的特点是将伪标签策略融入到标签传播过程中,并与基于特征的学习结合起来,共同用于评论者网络建模。在理论上可以证明该模型可被认为是在一个网络衍生合成数据集上的加权逻辑回归。通过描述网络的重要性、网络同质性的强度,并且刻画未标记数据的价值等丰富参数,使模型变得更加透明。在两个不同的真实数据集上的实验证明了我们模型的有效性和未标记数据的重要性。值得一提的是,经过适当修剪后的评论者网络显示出显著的同质性效应并发挥了至关重要的作用。特别地,本研究所提出的模型对标签的稀疏性和标签分布的有偏性均表现出一定的鲁棒性。
作者信息
Zhiang Wu(伍之昂,南京审计大学)
Guannan Liu*(刘冠男,北京航空航天大学,数据智能与智慧管理工信部重点实验室)
Junjie Wu(吴俊杰,北京航空航天大学,数据智能与智慧管理工信部重点实验室)
Yong Tan(谭勇,华盛顿大学)
引用信息
Zhiang Wu, Guannan Liu*, Junjie Wu, Yong Tan. Are Neighbors Alike? A Semi-supervised Probabilistic Ensemble for Online Review Spammers Detection. Information Systems Research (ISR). Accepted in Sep, 2023.
资助信息
This work was partially supported by Natural Scientific Foundation of China (NSFC) under grants 72031001, 72371011, 72072091, 72242101. Dr. Zhiang Wu was supported by Industry Projects in Jiangsu S&T Pillar Program under grant BE2023089.
02
全文简介
在线评论已经成为了亚马逊、淘宝、Yelp 等电商平台的显著特点,用户能够发表评分和评论,从而帮助潜在消费者直接了解产品和商家的更多信息。实际上,产品和商家的销量在很大程度上受到在线评论的影响,而有偏见的评分可能会反过来扭曲消费者对产品的认知。基于此,一些商家发现了可以通过操纵评分来获得利益的机会。例如,通过故意发布虚假评论来提高自己的评分或降低竞争对手的评分。由于从虚假评论中能够获得非法利益,有些虚假评论服务提供商可能会通过众包的方式雇佣真实的平台用户为目标商家或产品撰写虚假评论。我们在图1中展示了一个虚假评论服务提供商的屏幕截图,任务要求用户使用经过验证的真实姓名下订单,并在发送空包裹后,让用户发布5星级评分,最后用户在任务完成时可以获得一定数量的报酬。类似地,亚马逊也已经发现某些供应商出售和购买虚假评论的不当行为在平台上广泛存在。
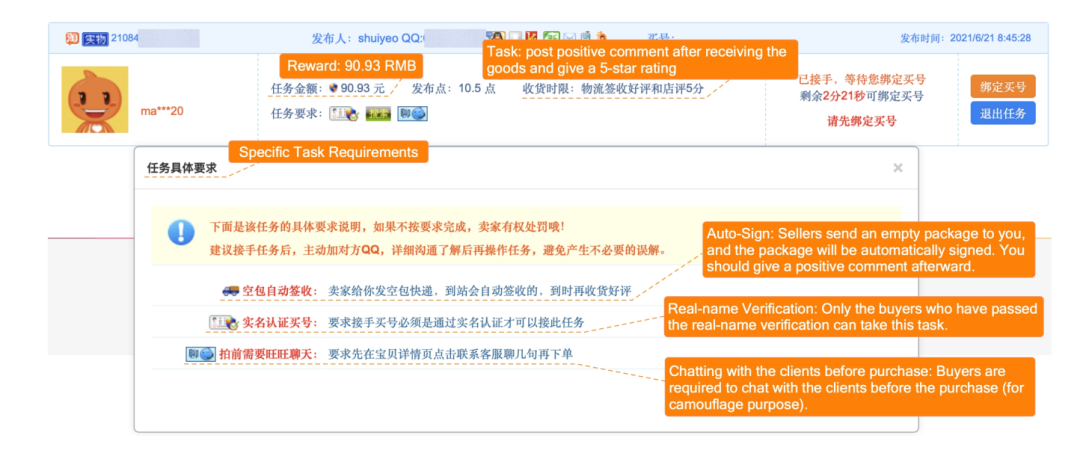
图1 淘宝虚假评论服务提供商发布的虚假评论写作任务示例
因此,虚假评论一直是维护公平和可信赖在线环境的主要威胁。据估计,像Yelp这样的在线评论平台中含有16%的虚假评论,大量的虚假评论会伤害用户对平台的信任。考虑到虚假评论和虚假评论者可能带来的危害,许多在线平台已经推出了过滤系统,来删除可疑的虚假评论并停用相关的虚假评论账户。但大多数现有的系统仍然严格依赖基于规则的过滤器,无法检测和阻止所有类型的虚假评论。特别是当虚假评论者的策略不断进化时,个体用户甚至可以巧妙地伪装他们在平台上的虚假评论行为,这就会使得基于规则的检测方法的局限性增大。
近年来,学术界和工业界都提出从不同的角度防止和检测虚假评论。然而,之前的方法存在几个显著的局限性。首先,虚假评论者检测问题通常是一个半监督学习问题,即只有一小部分用户被标记为虚假评论者,而其他用户的身份仍然未知。但是之前的检测方法通常强调部分标记的数据,导致虚假评论者检测的性能很容易受到部分标记数据中的噪音或偏差的影响。即使一些方法已经考虑在模型训练中加入未标记的数据,但未标记的数据是否以及如何帮助改善虚假评论检测尚待全面回答。例如,基于GCN的模型仅仅基于部分标记的数据构建损失函数,其中未标记的节点只能从标记的邻居处接收消息。其次,已有的检测模型通常缺乏灵活性,无法捕获不同节点的异构特征权重的细微差异和连接节点之间的同质性效应,以达到虚假评论者检测的目标。例如,基于GCN的模型考虑了邻居节点之间的消息传递和聚合机制,但这两者之间的影响通常通过分层权重矩阵保持一致,这无法明确区分具有不同身份的邻节点之间的不同影响。第三,尽管之前已经有工作同时考虑了个体行为特征和网络结构,但通常只关注一个特定的方面,缺乏一个协同学习机制,以相互获取补充信息。例如,基于图的排序方法利用了网络结构,但对节点特征的建模有所缺失。此外,在基于马尔可夫随机场(pMRF)的方法中,节点势能和边缘势能在消息传递期间始终保持静态,无法捕获标签推断、特征权重和邻居影响在传播过程中的协同更新。此外,哪种建模视角在确定评论者真实性方面起着更为重要的作用也还未得到明确的回答。
因此,为了解决虚假评论者检测问题中不同类型虚假评论者的固有挑战,我们在具有共同评论行为的用户之间构建了一个评论者网络,如图2所示。在该网络中,如果较多的邻居被识别为虚假评论者,则用户会更有可能被识别为虚假评论者。结合个人行为特征和评论者网络,我们提出了一个半监督概率协同学习模型,以整合虚假评论者检测的两个视角的协同效应。一方面,在给定部分标签和行为特征的情况下,我们构建了一个基于逻辑回归的模型来推导基于节点的预测。为了减轻部分标签带来的噪声或偏差的负面影响,我们采用了一种伪标签策略来全面利用未标记的数据,其中每个未标记的节点都被分配了一个伪标签,伪标签也同时被用于损失函数的构建,但同时会被赋予一个置信度权重。另一方面,我们在给定邻域信息的条件下,建模了用户是虚假评论者的条件概率;同时将评论者网络中相连邻居之间的同质性效应进行参数化,以适应迭代过程中邻居影响的变化。此外,我们通过交替更新伪标签、特征权重以及邻居之间的影响,设计了一个有效的协同学习框架,这可以等效地视为网络相关合成训练数据集上的加权逻辑回归。
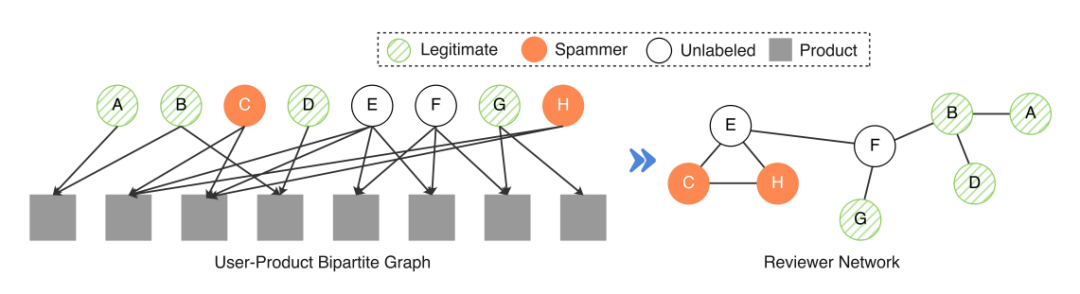
图2 评论者网络示例
我们在自建的亚马逊中国数据集和YelpNYC两个具有不同网络结构的真实评论数据集上验证了提出模型的有效性。与基线方法相比,我们的模型通常表现出优秀和稳健的检测性能。通过实验还得到了以下几方面的结论。首先,评论者网络中存在较强的同质性效应;因此,评论者网络权重的设定不宜过小,从而可以充分整合评论者网络以显著提高虚假评论者的检测性能。其次,在半监督学习框架下,给定有限的真实标签,未标记的数据对于提高检测性能非常有帮助,但是考虑到不确定性因素,从部分标记的数据推断出的伪标签置信权重不应被过分放大。此外,通过伪标签策略整合未标记的数据可以增强模型对网络中的标签稀疏性和有偏标签分布的稳健性。第三,通过合理的策略对评论者网络进行修剪,如适度的权重阈值、或者对网络边的有效约束等,对评论者网络发挥性能有着重要的作用。
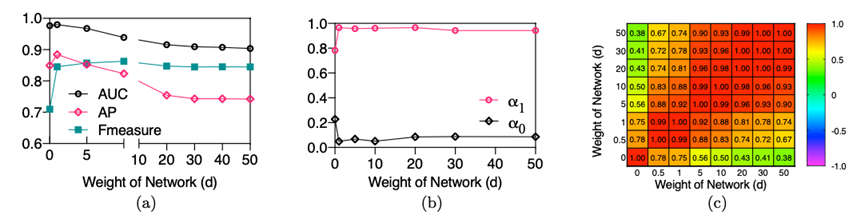
图3 评论者网络的参数设定对于检测效果有重要的作用,需要合理权衡,不宜设置太大或太小
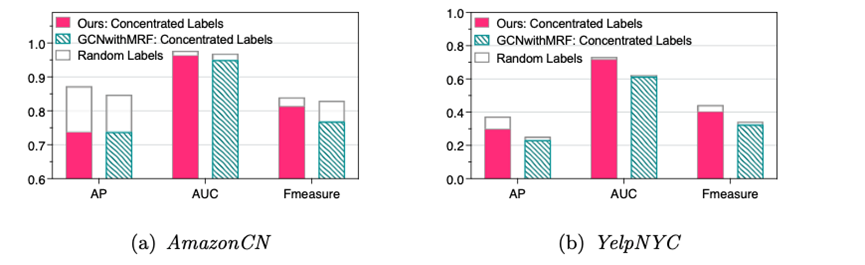
图4 标记数据在网络中的分布对检测结果有显著的影响,而我们提出的方法整体的鲁棒性较强






