在2023年10月被《INFORMS Journal on Computing》接收的论文《Deterring the Gray Market: Product Diversion Detection via Learning Disentangled Representations of Multivariate Time Series》(DOI: 10.1287/ijoc.2022.0155)中,实验室学者林浩助理教授、刘冠男副教授、吴俊杰教授以及香港中文大学(深圳)赵建良教授针对因供应链造假而形成的灰色市场(Gray Market)这一问题,提出了一种基于多元时序解耦表征学习的产品转移检测框架,文章的主要观点如下。
01
摘要
当一些分销商将产品转卖给未经授权的分销商或零售商,以从制造商处获取差异化渠道激励(例如数量折扣)时,就会出现灰色市场(Gray Market)。传统上,制造商严重依赖内部审计师定期调查产品和资金的流动来遏制灰色市场,但鉴于分销商和订单数量巨大,这种做法成本太高。数据分析技术的进步使得制造商能够轻易地将分销商在不同时间点订购的产品数量数据组织成多元时间序列,对其进行分析将有助于揭示可疑的产品转移行为并大幅缩小审核范围。有鉴于此,本文基于时间序列表示学习的最新进展,采用序列自编码器来实现分销商序列需求模式的整体表征;为了应对订货数量多元时间序列中潜在的大量耦合因素和噪声信息,本文提出一种解耦学习(disentangled learning)机制来增强序列表征;同时,考虑到不同分销商订货序列之间的潜在关联,本文还引入了一个分销商间相关性正则项,来确保更有效的序列表征;最后,考虑到检测任务的无监督特性和异常标签的高度稀缺性,本文采用一种深度生成模型刻画分销商序列表征的生成过程,进而估计其概率密度,从而获得用于判定分销商异常程度的分数。真实的分销渠道数据集和模拟数据集上的大量实验验证了模型的优越性和鲁棒性。此外,成本-收益分析实验表明,我们的模型可帮助制造商实现更有针对性和更低成本的分销商审计,以更高效地遏制灰色市场。
作者信息
Hao Lin(林浩,北京航空航天大学,数据智能与智慧管理工信部重点实验室)
Guannan Liu(刘冠男,北京航空航天大学,数据智能与智慧管理工信部重点实验室)
Junjie Wu(吴俊杰,北京航空航天大学,数据智能与智慧管理工信部重点实验室)
J. Leon Zhao(赵建良,香港中文大学(深圳))
引用信息
Hao Lin, Guannan Liu, Junjie Wu, J. Leon Zhao. Deterring the Gray Market: Product Diversion Detection via Learning Disentangled Representations of Multivariate Time Series. INFORMS Journal on Computing, 2023, DOI: 10.1287/ijoc.2022.0155, forthcoming.
(注:由于论文刚被接收,论文全文暂未见网;获取论文代码和数据:https://github.com/INFORMSJoC/2022.0155)
资助信息
This work was supported by National Natural Science Foundation of China (NSFC) under grant 72031001, 72371011, 72301017, 72242101.
02
全文简介
灰色市场是指授权分销商将从制造商订购的产品转售给未经授权零售商,从而形成的原始制造商无法控制的市场。当制造商在不同分销渠道中实施差异化定价策略时,灰色市场自然就会出现,灰色市场已成为时尚、电子、计算机等诸多行业的普遍现象。例如,制造商可以对订购量大的下游分销商推出数量折扣,以刺激销售。在此情形下,分销商可能会利用这种数量折扣,通过订购超过其实际需要数量的产品来获得数量折扣,然后以更高的价格将产品转售给未经授权的零售商,这就是通常所说的产品转移。据报道,著名计算机制造商惠普公司就曾遭受灰色市场的困扰。例如,惠普的其中一个分销商就曾利用数量折扣合同过量订购了笔记本电脑,并将其转移到灰色市场中,惠普还因其产品被转移到未经授权的渠道而对其分销商提起过诉讼。此外,中国惠普的多家授权分销商在灰色市场中结成了联盟,联盟中的某一分销商可能会过量订购以获得数量折扣,而联盟中的其他分销商则会缩减从制造商处订货的数量,之后,库存过剩的分销商会将多余的产品以折扣价分流给联盟内的其他分销商,所有分销商进而都可以享受到更大的折扣,但这却损害了惠普的利润和激励计划。
作为供应链欺诈的典型类型,灰色市场的产品转移已成为制造商、授权分销商以及最终消费者面临的长期挑战。据报道,在包括书籍、音乐和电影等版权作品在内的灰色市场中,每年灰色销售额可高达2200亿美元。由于分销渠道之间的产品转移和价格控制的无序性和低效性,灰色市场可能会导致利润的直接减少和渠道关系的恶化。有鉴于此,制造商一直在致力于寻找和尝试遏制灰色市场的方法,其中定期的突击审计被认为是防止灰色市场形成的常见策略,即通过监测分销商的订单和销售情况,制造商可以掌握产品和资金流向。然而,鉴于经济和时间成本的考量,这种对每个分销商进行内部审计的做法在实践中可行性较差。现代信息系统使企业能够以更有效的方式阻止灰色市场,例如现代企业常用的ERP系统,可用于记录订单、销售和库存等日常业务活动数据,因此每个下游分销商的订货数量记录可以帮助制造商通过数据驱动的方法调查产品转移。事实上,每个库存量单位(SKU)的需求可能会表现出一些时间规律,例如季节性波动、市场增长或市场衰退等。因此,我们可以通过跟踪目录中所有SKU的订货数量时间序列(TSOQ)来估计一般的需求模式,其中每个SKU对应多元时间序列中一个通道的数据。如果存在灰色市场,参与产品转移的分销商的TSOQ会与正常分销商表现出截然不同的模式。例如,过量订货的分销商可能会在全年持续保持较高的订货量,这与正常分销商的订货行为存在极大偏差。
尽管已有诸多研究从时间序列角度提出了解决异常检测问题的方法,但从该角度对灰色市场进行阻止的相关研究尚未得到学术界和工业界的足够重视。在产品转移检测的TSOQ监测方面存在以下几个关键挑战。首先,已有的时间序列异常检测方法主要侧重于提取能够反映时间序列异常情况的手工特征,这需要大量的领域知识。然而,以产品分销为目的的分销商的订货行为可能不会突然改变,并且其与正常分销商的订货行为偏差可能会持续较长的时间。例如,我们可能会看到其订货数量逐渐上升,并且持续高于其他分销商,但这无法从单个时间点的订货快照中捕获。因此,在短时间窗口内提取的手工特征可能并不有效。其次,每个分销商可能负责分销一系列不同类型的产品,并且它们之间存在一定的替代或互补关系,这映射到多元时间序列数据上时会产生多种耦合的复杂跨通道关系;同时,TSOQ中存在大量的极端值,例如突然变化的订货量和零订货量,TSOQ中的此类干扰信息可能会阻碍正常订货模式的识别。此外,分销商之间的订货行为也可能存在相关性,如何对这样的相关性模式进行捕获也是一个难点。由于市场的一些系统性变化,分销商之间可能会表现出相似的订货行为,呈现出正相关模型;而异常分销商由于其订货数量的膨胀,可能会与其他分销商之间产生显著不同的相关性模式。
为解决上述挑战,本文提出一种多元时间序列解耦表征学习方法(模型框架如图1所示),以学习更具表达能力的TSOQ表征,并刻画分销商的整体订货行为特征。具体来说,本文采用序列自编码器通过重构TSOQ的方式来获得多元时间序列的表征。同时,本文设计了一个基于对抗训练的解耦学习层,以解除不同SKU中潜在的多种复杂跨通道关系之间的耦合性,并减少TSOQ中多种干扰信息的负面影响。通过这种方式,原始的TSOQ可以分解表征为多个潜在表示向量片段,每个片段可指示不同的订货模式。此外,为了考虑分销商之间的相关性模式,还在目标函数中设计了时间序列的相关性正则约束项,以增强序列表征。为适配异常检测任务,本文进一步通过高斯混合模型估计序列表征的概率密度并获得相应的异常得分,其中序列表示学习和异常检测任务的损失函数被集成在一个统一的目标函数中以端到端的方式进行优化。
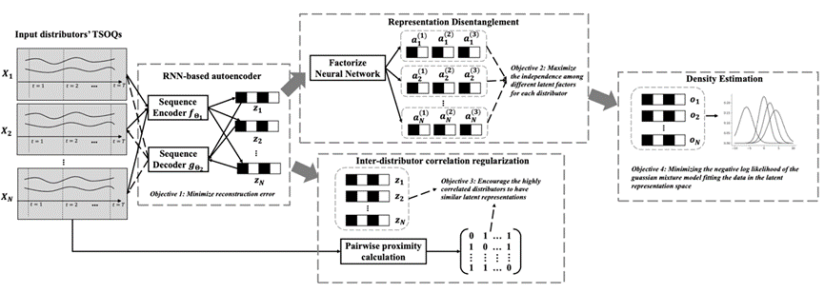
图1:模型框架示意图(模型包含基于RNN的自编码器、表征解耦模块、分销商间相关性正则约束模块、基于深度高斯混合模型的密度估计模块)
本文在一个标签分布不均衡的真实计算机制造商分销渠道数据集上证明了所提方法的有效性。实验结果表明,与基线方法相比,我们的方法在以AUROC和AUPRC为指标衡量的整体检测性能方面表现更优(如图2所示)。同时解耦学习、相关性正则约束等核心模块都被证明在保证模型检测性能方面发挥着至关重要的作用。我们将模型学得的序列低维表征向量进一步通过t-SNE方法投射到二维空间中,图3所示结果表明我们的方法能够在表征空间中清晰地将正常和异常分销商区分开来。我们还通过经济分析(也称为成本-收益分析)实验(如图4所示),验证了我们的模型可帮助制造商实现更有针对性和更低成本的分销商审计,同时,我们方法的利润曲线在所有基线方法之上,表明我们的方法总体上可获得更高的经济价值。为了进一步验证方法的稳健性,我们通过基于代理的仿真(Agent-based Simulation)技术模拟生成分销商资料以及对应的订货行为数据,并在训练和测试集中注入不同比例的异常产品转移行为数据,在不同异常比例设置下我们的模型均获得了更优的检测效果。
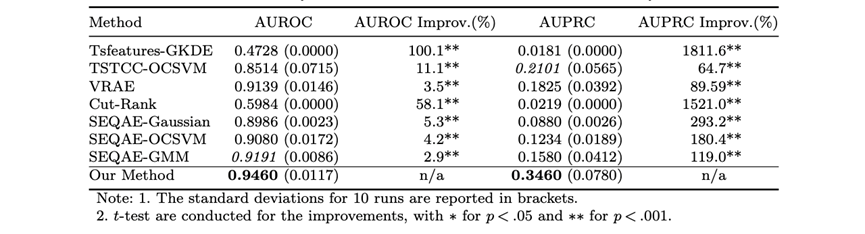
图2:真实分销渠道数据集上的模型检测性能对比结果(最优结果以粗体突出显示,次优结果以斜体显示。我们的方法在AUROC和AUPRC方面优于所有基线,并且在AUPRC方面提升更为明显;同时统计检验结果表明,我们的方法显著优于基线方法。)
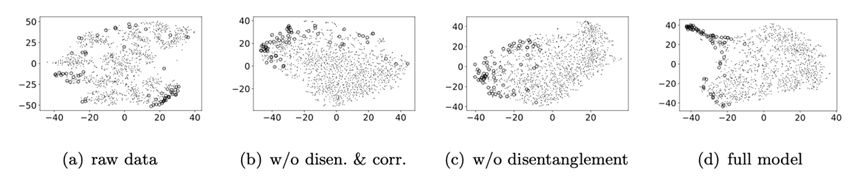
图3:分销商序列表征的t-SNE可视化结果(我们在真实分销渠道数据集上使用t-SNE将高维数据映射到二维空间进行可视化。具体地,我们分别对原始时间序列、我们模型的两个变体以及我们的模型学得的序列表征进行可视化,其中真实的异常数据用空心大圆圈突出显示,而正常数据则用小实心点标记。结果表明,我们的方法能将异常数据推离到一些低密度区域,从而清晰地区分正常和异常数据点。)
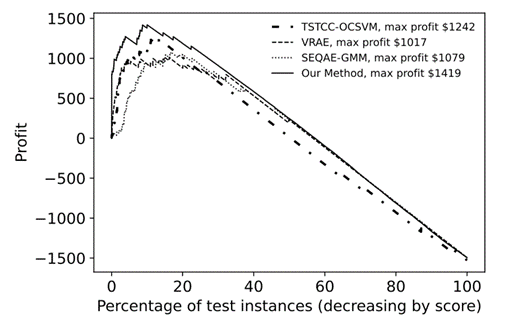
图4:模型成本-收益分析结果(一般而言,在真实分销渠道数据集上,给定每个模型输出的分销商异常得分,我们需要定义一个阈值来判定该分销商是否为异常,进而计算该模型的成本和收益以及对应的经济价值。本实验通过改变该阈值(图中横坐标数值),获得利润曲线。从结果可看出,我们方法的利润曲线在所有基线方法之上,表明我们的方法总体上可获得更高的经济价值。)






